MegaSquirt-II code version 2.83 and up have an α-β-γ (called "alpha-beta-gamma") filter on the tach input to properly take into account the varying speed of the crankshaft when making predictions for ignition timing. (This replaces the previous 'first derivative' and '2nd derivative' prediction options).
All the derivative prediction options were removed from the code and replaced with either Last Interval or alpha-beta-gamma. The latter is very similar to the derivative predictions already in there, but they are in a form that greatly simplifies the calculations, plus they are tunable. There are 3 new inputs for this.
In estimating the future position of an object (like a ballistic missile) or an event (like a tach zero-crossing), there are a number of ways to go about it. The simplest is to assume it has moved the same amount in the next time interval that it did in the last time interval. This is the same as assuming the speed is constant. In MegaSquirt-II, this is the 'last interval' algorithm.
The next simplest is to assume the interval will change by some percentage (the predictor gain %) of the change between the last two measured intervals. If we calculate the acceleration over recent intervals, we can apply an additional correction.
For example, suppose we want to calculate when a quick drag racer car that can run the ¼ mile in less than 10 seconds will cross the finish line in the ¼ mile, based on its speed and time at the 60 foot mark. Suppose we had the 0-60 foot time, and it was 2 seconds, and the car was going 60 miles/hour (88 feet/second) at that point. Then, a first approximation would be:
Δ means a small change in the value to the right, so Δt = t - t0. Similary, ΔV = V - V0
Since the time to cover distance x with acceleration a is T = √[2X/a]. Also, note that we had to know the position (60 feet) and the velocity (88 feet/sec) to get the acceleration.
You might remember this from your high school physics class that you can calculate the position X of an object at time t from it's initial position X0, initial velocity V0, and acceleration a:
We used this above to determine the time t to reach distance X, since X0 = V0 = 0 at time = 0, we have:
X = X0 + V0t + ½at2
= 0 + 0*t + ½at2
= ½at2
which can be rearranged using basic algebra as:
(the math symbol ⇒ means 'the above implies'; √ means take the square root of the value to the right)
The first time estimate is certainly too long. The second estimate is closer, but still too long. The last is closer again, but too short (and caused by the fact that the car's acceleration will taper off at high speed due to aerodynamic loads, etc.). However, the last prediction (7.75 seconds) is likely to be much closer to the actual ET than the first two.
You can see that adding the velocity and acceleration measurements greatly improves the prediction accuracy. The situation is similar for calculating the time for the next tach trigger to arrive (which is critical to getting the timing correct, since we want to fire before top dead center, and we only have the position of the previous top dead centers to guide us).
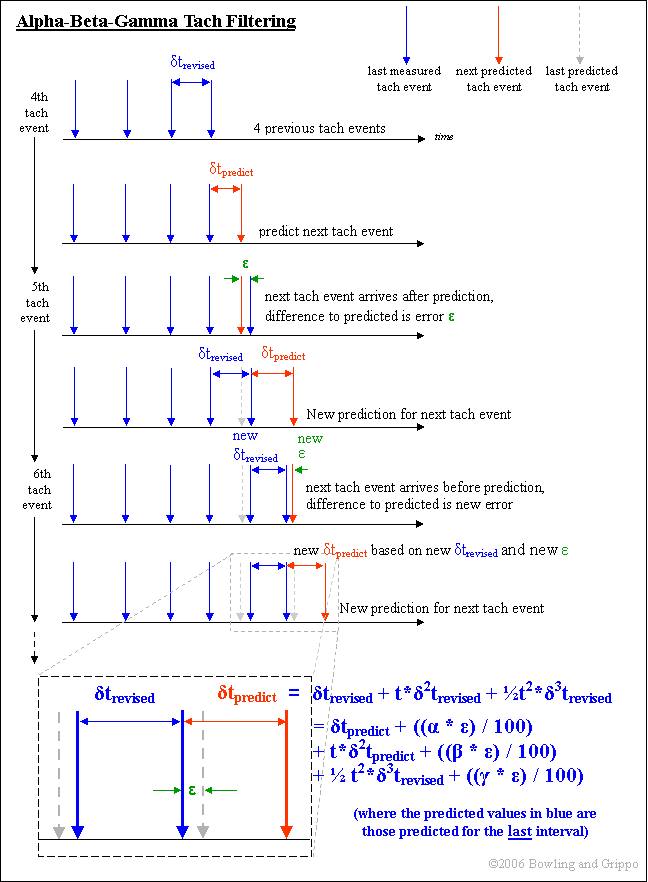
The are a few differences though. One is that we are trying to predict δt - the time to the next tach trigger event. The other difference is that we are not making a single computation, we are computing a prediction after each event, and we can use the measurements of the previous tach events to 'fine-tune' or prediction. The factors we use for fine-tuning are the values of α, β, and γ which is where the name of the filtering method comes from.
For our EFI application, we have an changing δt (if we knew t exactly, we wouldn't need to predict!). So instead of trying to predict X, we are trying to predict the change in ΔT - i.e., how much the time will change to the next tach event compared to what we measured between the last two tach events. In the analogy above, it is equivalent to measuring the time every 60 feet, and using that time (and the immediate previous ones) to compute the change in the time it will take to cover the next 60 feet.
We switch the notation from Δ to δ to denote small changes in values. This has significant meaning in calculus, but we will skip over a rather long explanation here. Note that you should think of δ as the math symbol for a small change in the value to its immediate right - trevised in the case of δtrevised, for example. δ2 means the rate of change of the change in the value to the right, that is, the velocity of the change. δ3 means the rate of change of the velocity in the value to the right, that is, the acceleration of the change.
The relevant code snippet looks like this:
errt = dt3[ICint] - dtpred; .... // alpha-beta-gamma filter prediction dts = dtpred + ((inpram.alpha * errt) / 100); tddts = tddtpred + ((inpram.beta * errt) / 100); t2dddts = t2dddts + ((inpram.gamma * errt) / 100); dtpred = dts + tddts + (t2dddts >> 1); tddtpred = tddts + t2dddts;
This may be a bit daunting to read (for non-programmers, at least), so lets ''clean it up' a bit by putting it into math terms rather than computer programming langauge:
First, note that '>> 1' is the programmer's way of saying divide by 2 (It is actually a binary right shift of one bit, which effectively divides by 2). So '>> 2 woulf be divide by 4, '>> 3' would be divide by 8, etc. And we have '<<' as well, and '<< 3' would be multiply by 8, etc..
Let:
Note that values with a 'predict' subscript (such as δtpredict) are predicted values that are computed for the next tach event. Values with a 'revised' subscript (such as δtrevised) are values revised from the most recent observed (measured) tach events that have already happened. Note that there are a predicted and an measured values for each of the quantities (except the error (ε) which is the difference between the measured and predicted values, and t2*δ3t, which is not predicted).
Then our code's equations become:
ε = δtrevised - δtpredict
The actual interval is compared to the predicted interval, and the difference is ε,δtrevised ← δtpredict + ((α * ε) / 100);
We add α/100 * last error (ε) to the last predicted interval to get δtrevised - the change based only on the last intervalt*δ2trevised ← t*δ2tpredict + ((β * ε) / 100);
This is analogous to the V0t term above [δ2trevised is similar V], it is the velocity component, but corrected using the beta gain factor,t2*δ3trevised ← t2*δ3trevised + ((γ * ε) / 100);
This is analogous to the at2 term above [δ3trevised is similar to a], it is the acceleration component, but corrected using the alpha gain factor,δtpredict ← δtrevised + t*δ2trevised + ½ t2*δ3trevised;
Note the similarity to X = X0 + V0t + ½at2, and also that we start over from the revised (measured values, so X0 (δtrevised) is the actual measured (i.e., 'revised') interval, etc.)t*δ2tpredict ← t*δ2trevised + t2*δ3trevised;
Update the predicted velocity for the next time through the loop.(← means the equation on the right is evaluated, and assigned to the variable on the left)
A few other things to note here:
The alpha value (aka. "alpha gain") is like the proportional value in the ego loop, the beta is equivalent to 1st derivative weighting and gamma to 2nd derivative. The defaults are the best place to start.
The value of alpha will be typically be 90 to 100% or a bit higher.
The value of beta will be moderately small so that speed estimates are not unduly affected by variations from input data. A typical value is around 5% to 80%.
The gamma gain term helps to track changes with less sensitivity to input data. The alpha helps to maintain consistency between the velocity and acceleration variables. A typical value is around 10%.
But why use the alpha-beta-gamma factors at all? Why not just use 100% for all of them, and let the prediction work it's 'mathematical magic'? There are three reasons:
The way we do this averaging IS with the alpha-beta-gamma gain factors.
MegaSquirt-II includes the timing error in it's datalogs (in those code versions that have alpha-beta-gamma filtering, at least), in a field called 'timingErr'. When tuning the filters, you can monitor this field in real-time in MegaTune (right click on a gauge and 'swap to' Timing Errr) or examine it with a datalog viewer (it is logged automatically), You goal is to minimize the error, under as many conditions as you can.